
Nvidia Advances AI with Open Source Release of KAI Scheduler
Nvidia has taken a significant step in enhancing the artificial intelligence (AI) and machine learning (ML) landscape by open-sourcing the KAI Scheduler from its Run:ai platform. This move, under the Apache 2.0 license, aims to foster greater collaboration and innovation in managing GPU and CPU resources for AI workloads. This initiative is set to empower developers, IT professionals, and the broader AI community by providing advanced tools to efficiently manage complex and dynamic AI environments.
Understanding the KAI Scheduler

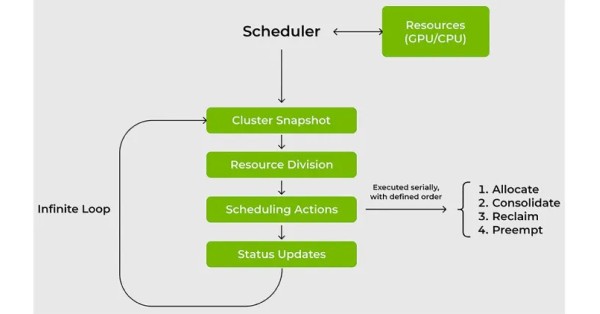
The KAI Scheduler, originally developed for the Nvidia Run:ai platform, is a Kubernetes-native solution tailored for optimizing GPU utilization in AI operations. Its primary focus is on enhancing the performance and efficiency of hardware resources across various AI workload scenarios. By open sourcing the KAI Scheduler, Nvidia reaffirms its commitment to the support of open-source projects and enterprise AI ecosystems, promoting a collaborative approach to technological advancements.
Key Benefits of Implementing the KAI Scheduler
Integrating the KAI Scheduler into AI and ML operations brings several advantages, particularly in addressing the complexities of resource management. Nvidia experts Ronen Dar and Ekin Karabulut highlight that this tool simplifies AI resource management and significantly boosts the productivity and efficiency of machine learning teams.
Dynamic Resource Adjustment for AI Projects
AI and ML projects are known for their fluctuating resource demands throughout their lifecycle. Traditional scheduling systems often fall short in adapting to these changes quickly, leading to inefficient resource use. The KAI Scheduler addresses this issue by continuously adapting resource allocations in real-time according to the current needs, ensuring optimal use of GPUs and CPUs without the necessity for frequent manual interventions.
Reducing Delays in Compute Resource Accessibility
For ML engineers, delays in accessing compute resources can be a significant barrier to progress. The KAI Scheduler enhances resource accessibility through advanced scheduling techniques such as gang scheduling and GPU sharing, paired with an intricate hierarchical queuing system. This approach not only cuts down on waiting times but also fine-tunes the scheduling process to prioritize project needs and resource availability, thus improving workflow efficiency.
Enhancing Resource Utilization Efficiency
The KAI Scheduler utilizes two main strategies to optimize resource usage: bin-packing and spreading. Bin-packing focuses on minimizing resource fragmentation by efficiently grouping smaller tasks into underutilized GPUs and CPUs. On the other hand, spreading ensures workloads are evenly distributed across all available nodes, maintaining balance and preventing bottlenecks, which is essential for scaling AI operations smoothly.
Promoting Fair Distribution of Resources
In environments where resources are shared, it’s common for certain users or groups to monopolize more than necessary, potentially leading to inefficiencies. The KAI Scheduler tackles this challenge by enforcing resource guarantees, ensuring fair allocation and dynamic reassignment of resources according to real-time needs. This system not only promotes equitable usage but also maximizes the productivity of the entire computing cluster.
Streamlining Integration with AI Tools and Frameworks
The integration of various AI workloads with different tools and frameworks can often be cumbersome, requiring extensive manual configuration that may slow down development. The KAI Scheduler eases this process with its podgrouper feature, which automatically detects and integrates with popular tools like Kubeflow, Ray, Argo, and the Training Operator. This functionality reduces setup times and complexities, enabling teams to concentrate more on innovation rather than configuration.
Nvidia’s decision to make the KAI Scheduler open source is a strategic move that not only enhances its Run:ai platform but also significantly contributes to the evolution of AI infrastructure management tools. This initiative is poised to drive continuous improvements and innovations through active community contributions and feedback. As AI technologies advance, tools like the KAI Scheduler are essential for managing the growing complexity and scale of AI operations efficiently.















