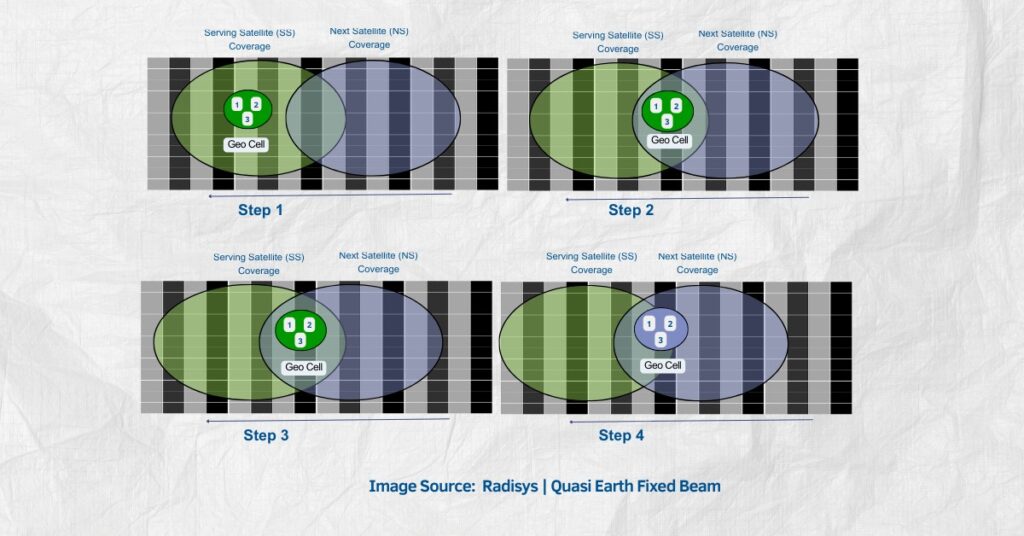
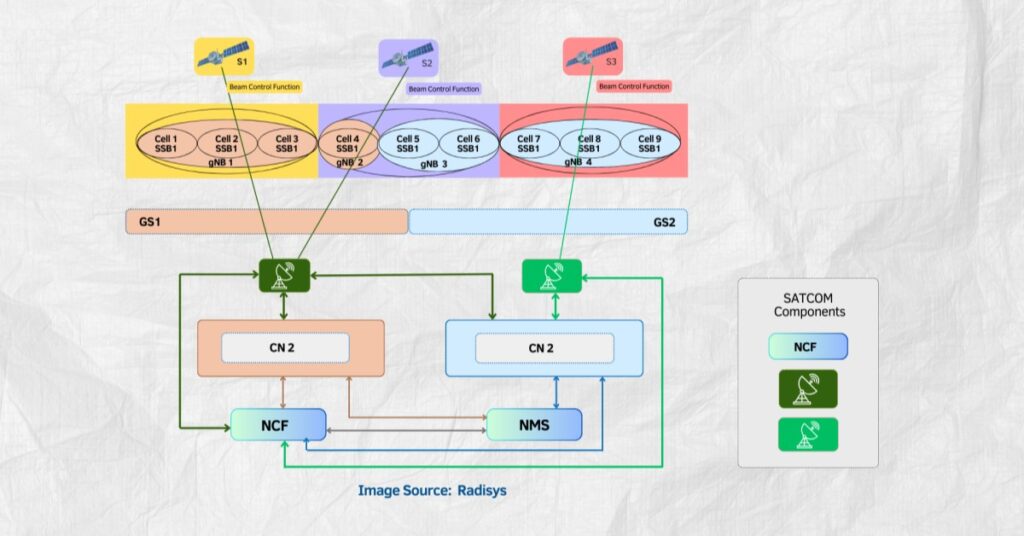
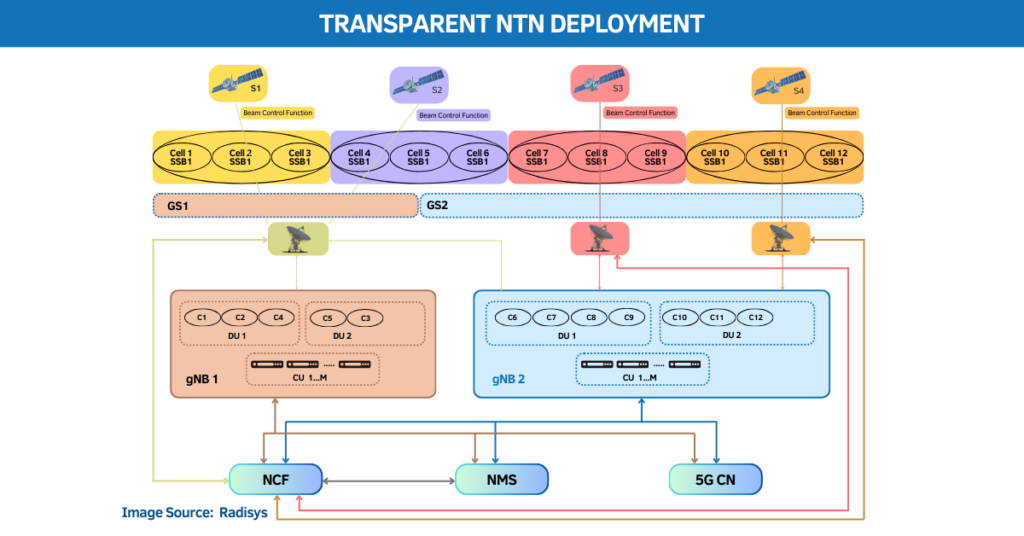
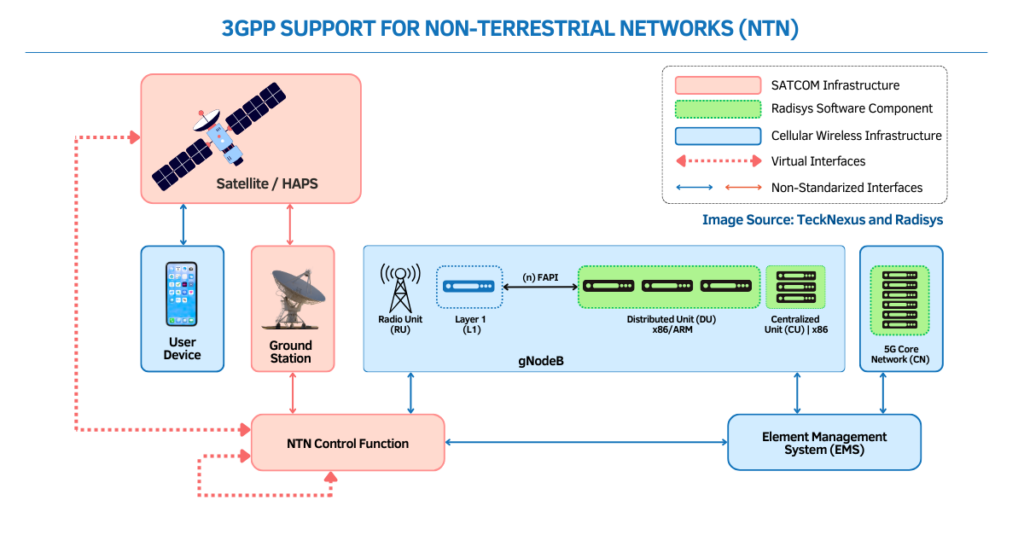
Nvidia has unveiled a new breakthrough in AI processing, one that could redefine how large language models (LLMs) handle massive volumes of data without sacrificing responsiveness.
Dubbed Helix Parallelism, the technique enables AI agents to work with million-token contexts — think entire encyclopedias — while maintaining real-time speed. This marks a major step in overcoming one of the biggest headaches in modern AI: how to remember everything while staying fast.

DNA-Inspired Parallelism for Massive Contexts
According to Nvidia’s research team, Helix Parallelism solves long-standing memory bottlenecks that crop up when LLMs process sprawling documents or maintain continuity in lengthy chats.
“Inspired by the structure of DNA, Helix interweaves multiple dimensions of parallelism — KV, tensor, and expert — into a unified execution loop,” explained the Nvidia researchers in a recent blog. This multi-layered approach lets each processing stage handle its own workload while sharing GPU resources more efficiently.
Helix Parallelism Optimized for Blackwell GPUs
Helix Parallelism is designed to run on Nvidia’s latest Blackwell GPU architecture, which supports high-speed interconnects that allow GPUs to share data at lightning speed. By distributing tasks like memory streaming and feed-forward weight loading across multiple graphics cards, Helix sidesteps common choke points that slow down AI models working with ultra-long contexts.
Simulations show impressive gains. Compared to earlier methods, Helix can boost the number of concurrent users by up to 32 times while staying within the same latency budget. In lower concurrency settings, response times can improve by up to 1.5x.
Why It Matters: The Context Window Challenge
Most modern LLMs struggle with what experts call the “lost in the middle” problem: as conversations grow longer, models forget what came earlier. Limited context windows mean only a fraction of the available data is used effectively.
Key-value cache streaming and the repeated loading of feed-forward weights have traditionally eaten up memory and bandwidth, throttling performance. Helix Parallelism addresses both, splitting these heavy workloads and orchestrating them so no single GPU gets overwhelmed.
“This is like giving LLMs an expanded onboard memory,” said Justin St-Maurice from Info-Tech Research Group. “It’s a shift that brings LLM design closer to the advances that made older chips like Pentiums work smarter.”
Helix Parallelism: Enterprise Use Cases & Limitations
There’s no doubt Helix Parallelism is a feat of engineering, but some industry voices question its near-term fit for everyday enterprise use.
Wyatt Mayham, CEO at Northwest AI Consulting, points out that while the technology solves real problems like quadratic scaling and context truncation, “for most companies, this is a solution looking for a problem.” In most enterprise workflows, he argues, smarter retrieval-augmented generation (RAG) pipelines that surface only the “right” data are still more practical than brute-force million-token brute force.
However, for niche applications that demand full-document fidelity, such as legal research, compliance-heavy audits, or AI medical systems analyzing a patient’s lifetime health records, Helix’s capabilities could be transformative.
St-Maurice agrees: “This is about enabling LLMs to ingest and reason across massive data sets, maintaining context without losing coherence.”
Applications: From Legal Research to Coding Copilots
Nvidia sees Helix Parallelism as a catalyst for building more sophisticated AI agents. Imagine a legal assistant parsing gigabytes of case law in one go, or a coding copilot that can navigate huge repositories without losing track of dependencies.
More broadly, the technique could enable multi-agent AI design patterns, where separate LLMs share large context windows, coordinate tasks, and collaborate in real-time. This unlocks new directions for AI development in complex environments.
Hardware-Software Co-Design: A Critical Frontier
The push behind Helix shows Nvidia’s continued focus on deeply integrated hardware-software design, rather than relying solely on algorithm tweaks. Still, the hardware lift remains massive: moving massive chunks of contextual data through GPU memory comes with inherent latency risks.
St-Maurice cautions that data transfer across memory hierarchies remains a big obstacle. “Even with breakthroughs like Helix, optimizing data flow will be the next frontier.”
What’s Next for Helix Parallelism & Real-Time AI
Nvidia plans to roll Helix Parallelism into its inference frameworks for a range of applications, promising that more responsive AI systems — capable of digesting encyclopedia-length content on the fly — are closer than ever.
Whether it becomes a game-changer for day-to-day business or remains a high-end tool for specialized fields will depend on how organizations balance the power of bigger context windows against the cost and complexity of massive GPU clusters.
One thing is clear: as AI continues to evolve, breakthroughs like Helix Parallelism push the boundaries of what’s possible — and raise the bar for what’s practical.