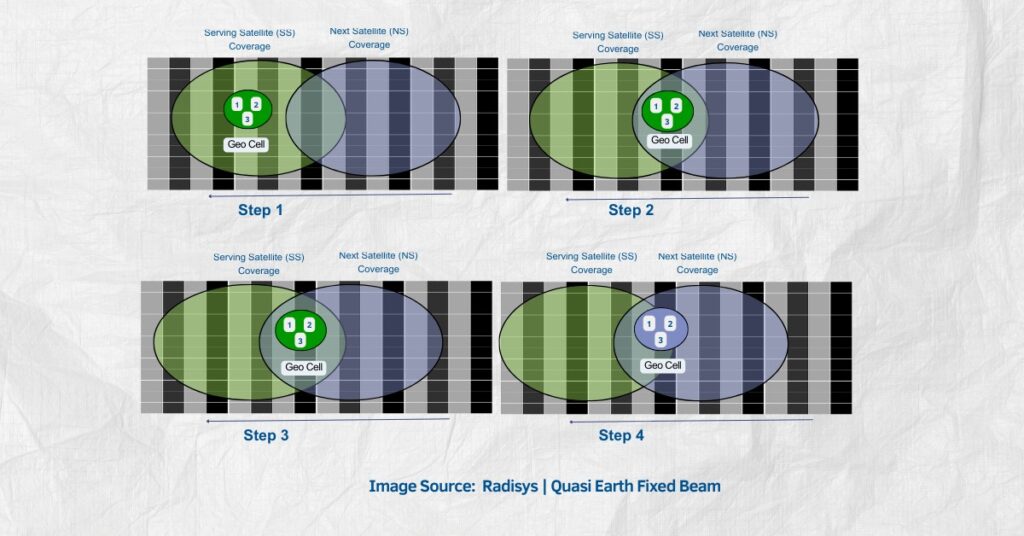
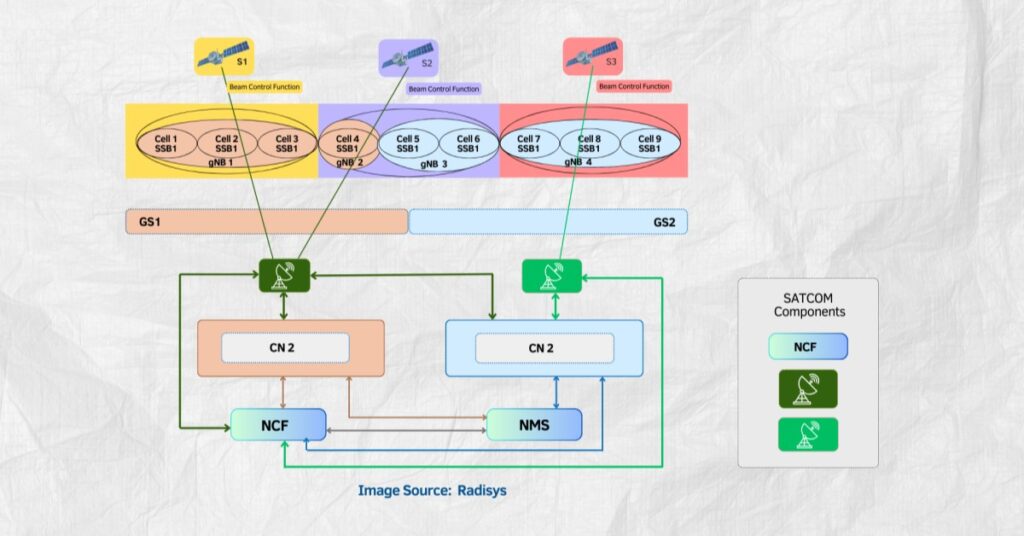
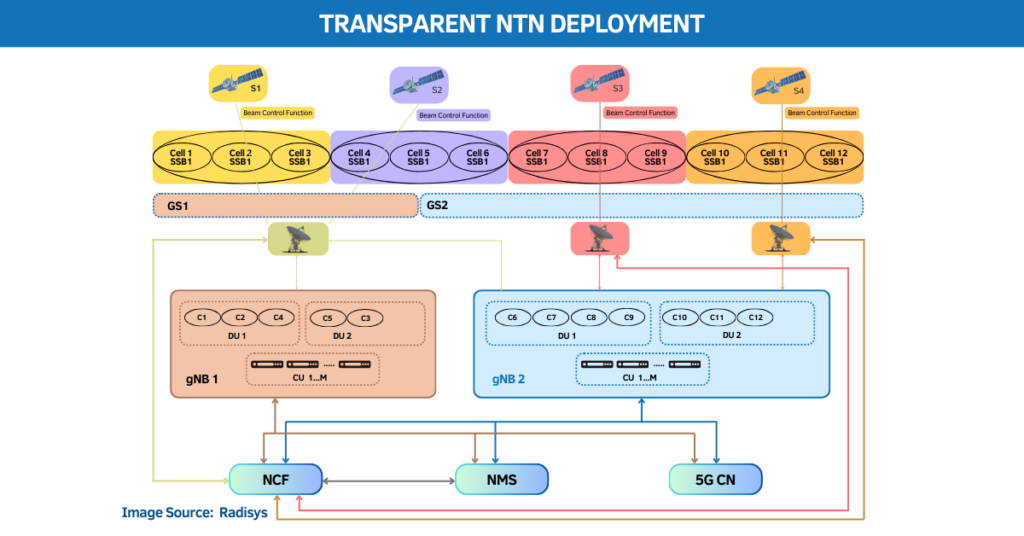
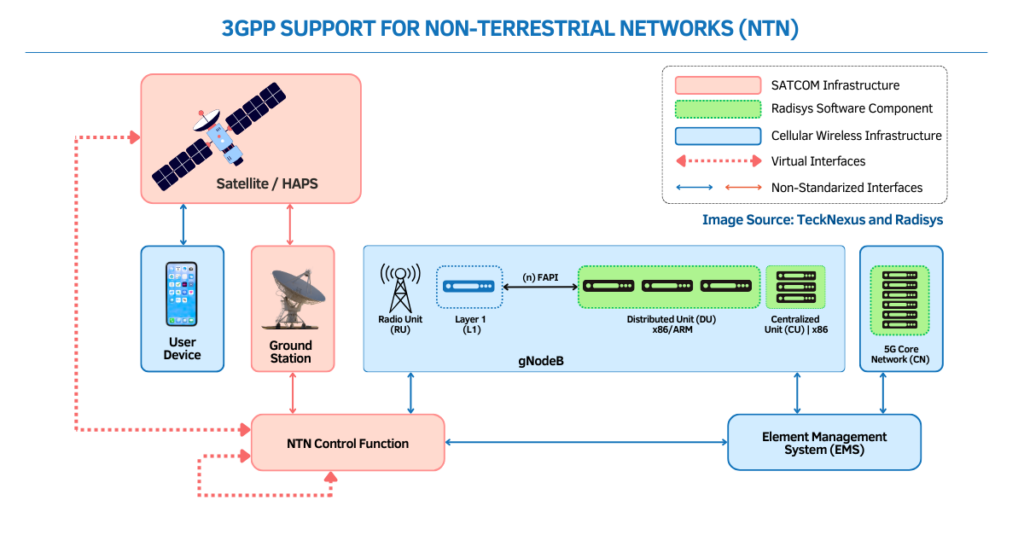
Hitachi’s NVIDIA-Powered AI Factory Overview
Hitachi has launched a global AI Factory built on NVIDIA’s reference architecture to speed the development and deployment of “physical AI” spanning mobility, energy, industrial, and technology domains.
Hitachi’s Standardized NVIDIA AI Stack Announcement
Hitachi is standardizing a centralized yet globally distributed AI infrastructure on NVIDIA’s full-stack platform, pairing Hitachi iQ systems with NVIDIA HGX B200 platforms powered by Blackwell GPUs, Hitachi iQ M Series with NVIDIA RTX 6000 Server Edition GPUs, and the NVIDIA Spectrum-X Ethernet AI networking platform. The environment is designed to run production AI with NVIDIA AI Enterprise and support simulation and physically accurate digital twins using NVIDIA Omniverse libraries. The AI Factory underpins Hitachi’s Lumada 3.0 strategy and expands the company’s HMAX portfolio—its suite of AI-enabled solutions already applied in rail operations, asset maintenance, and industrial optimization.

Why Physical AI and AI Factories Matter Now
Enterprises are moving beyond LLM pilots to AI that perceives, decides, and acts in the physical world, where latency, safety, and reliability dominate requirements. By combining OT know-how with accelerated computing and an Ethernet-based AI fabric, Hitachi aims to shorten time-to-value for AI in plants, grids, railways, and critical infrastructure. For telecom and enterprise IT leaders, this is a marker that “AI factories” are becoming the organizing construct for large-scale, cross-domain AI, with implications for edge architecture, data sovereignty, energy consumption, and IT/OT operating models.
AI Factory Architecture: Compute, Networking, Deployment
The design blends standardized compute with AI-ready networking and software to support training, simulation, and fast inference for real-world operations.
Compute and Software: Blackwell, RTX, AI Enterprise, Omniverse
At the core are NVIDIA Blackwell-based HGX B200 systems for training and complex model tuning, complemented by NVIDIA RTX 6000 Server Edition GPUs for scalable inference and visualization workloads. The stack is anchored by NVIDIA AI Enterprise for lifecycle management and optimized frameworks, and Omniverse libraries to build and run industrial digital twins using open scene description technologies such as OpenUSD. This combination supports the progression from model development to high-fidelity simulation to operational deployment—critical for safety cases and compliance in regulated sectors.
Ethernet AI Fabric and Data Movement with Spectrum-X
NVIDIA Spectrum-X provides an Ethernet AI networking fabric engineered for consistent, low-latency, high-throughput training and inference clusters. For operators already standardized on Ethernet, this reduces integration friction versus alternative interconnects and can simplify multi-tenant designs. The emphasis on congestion control and telemetry in AI Ethernet fabrics aligns with the need to move large sensor, video, and logs between edge sites, data centers, and digital twin environments without compromising determinism.
Distributed Topology and Data Sovereignty
The AI Factory spans the United States, EMEA, and Japan, enabling low-latency access for engineers and adherence to regional data residency requirements. This topology supports hybrid patterns where data is captured and processed near the source—such as at a depot, substation, or cell site—while model training, simulation, and governance occur in regional hubs, then distilled models are deployed back to the edge for real-time decisioning.
Physical AI Use Cases for Mobility, Energy, and Telco
The platform is optimized for applications that sense, simulate, and act across critical infrastructure and industrial environments.
Mobility and Rail: Maintenance, Safety, Scheduling
Hitachi’s HMAX solutions already apply computer vision and predictive analytics to rail maintenance, incident response, and timetable optimization. With the AI Factory, these applications can incorporate richer simulation via digital twins, enabling scenario testing for rolling stock reliability, platform safety analytics, and workforce scheduling—while informing real-world interventions through connected assets.
Energy and Industrial: Inspection, Optimization, Sustainability
Utilities and manufacturers can use physical AI to fuse sensor streams with 3D facility models, automating inspection, anomaly detection, and process optimization. Combined with generative AI for work instructions and engineering assistants, operators can reduce downtime and improve yield. The inclusion of liquid-cooled AI data centers supports rising power densities, aligning with Hitachi’s Green Transformation goals to curb energy waste and water usage while lifting performance per watt.
Telco: Network Digital Twins and Edge Inference
Telecom operators can leverage the same stack to build RF and transport network digital twins, test RAN parameter changes before live deployment, and run AI inference for quality-of-experience assurance at the edge. As 5G Advanced and private cellular expand, physical AI can enhance site safety monitoring, automate field inspections, and orchestrate edge workloads alongside network functions, improving resilience and opex efficiency.
Strategic Implications: OT/IT, Sustainability, Sourcing
The move signals how AI factories will reshape operating models, infrastructure choices, and sustainability strategies.
OT/IT Convergence and Co-Creation with Lumada
Hitachi’s Lumada framework blends domain expertise, systems integration, and data services to co-create AI with customers. For operators and enterprises, the lesson is to align AI roadmaps with safety management systems, reliability engineering, and change control—treating digital twins and simulation as mandatory gates for physical AI deployment, not optional accessories.
Sustainability and Liquid Cooling Economics
Liquid cooling is becoming a design prerequisite for dense AI clusters. Planning must include facility retrofits, thermal envelopes, and lifecycle carbon impacts. The business case should weigh power usage effectiveness, water usage, and serviceability against throughput gains; many regulators now expect clear reporting as part of broader ESG disclosures, especially for public infrastructure.
Build vs. Buy: AI Factory Deployment Options
With standardized reference designs and managed software stacks, enterprises can choose between on-premises AI factories, colocation with liquid-cooling support, or consumption via service providers. Evaluate Ethernet-based AI fabrics like Spectrum-X against existing data center networks, consider data gravity for sensor-rich workloads, and ensure MLOps, safety cases, and governance can operate consistently across regions.
Next Steps for Telecom and Enterprise IT Leaders
Executives should translate the AI Factory concept into near-term pilots with a clear path to scale, anchored in measurable business outcomes.
Immediate Actions for Pilots and Governance
Identify two to three physical AI use cases that benefit from simulation-first workflows—such as visual inspection, worker safety analytics, or network optimization—and define the data contracts and KPIs. Assess site readiness for liquid cooling and power density, and benchmark Ethernet AI fabric performance against your target training and inference profiles. Establish a governance framework spanning data provenance, model risk management, and safety validation using digital twins before live rollouts.
What to Watch: Blackwell, Spectrum-X, Omniverse, HMAX
Track performance and efficiency gains from NVIDIA Blackwell-based systems, the maturity of Spectrum-X in multi-tenant and hybrid topologies, and interoperability advances in Omniverse and OpenUSD for industrial twins. Watch how Hitachi evolves HMAX across mobility, energy, and industrial customers, and how Lumada 3.0 embeds co-creation and sustainability metrics into AI delivery. For telecoms, monitor integrations that tie network telemetry into twin-driven optimization and the migration of AI inference to edge sites alongside 5G and MEC workloads.