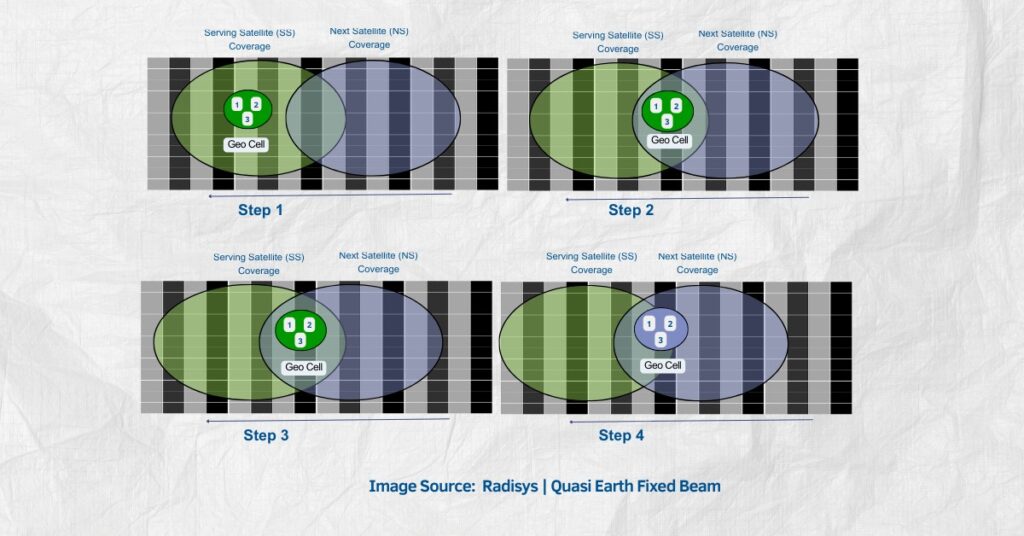
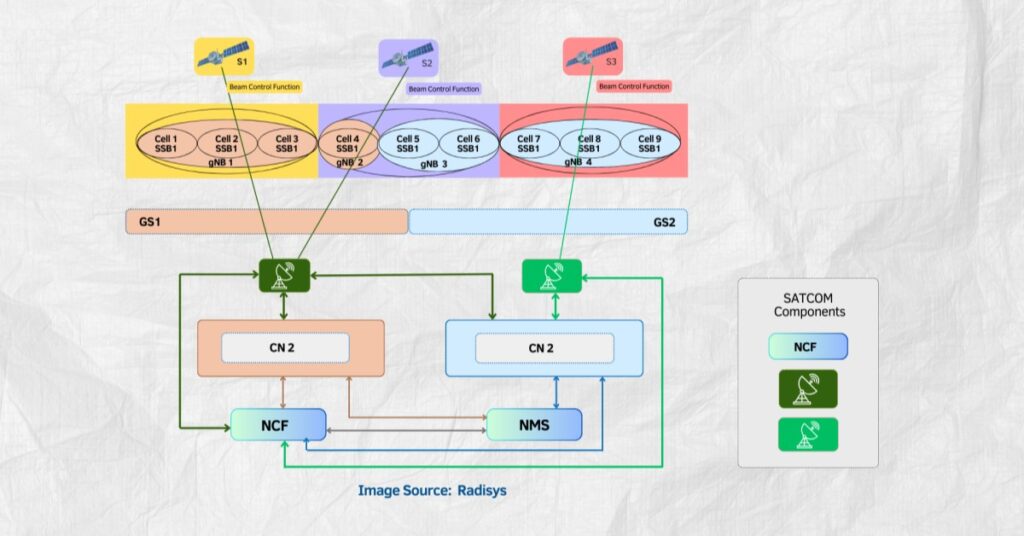
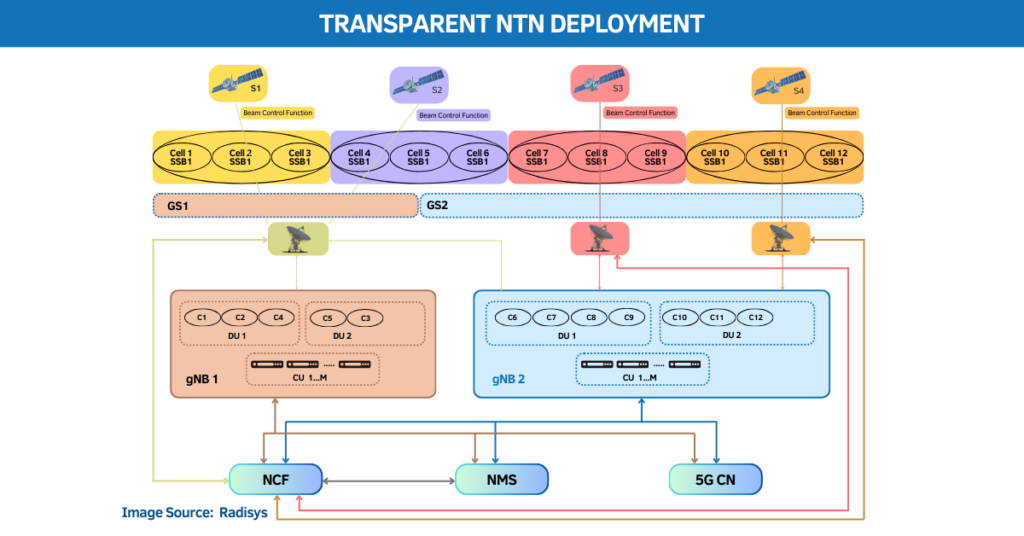
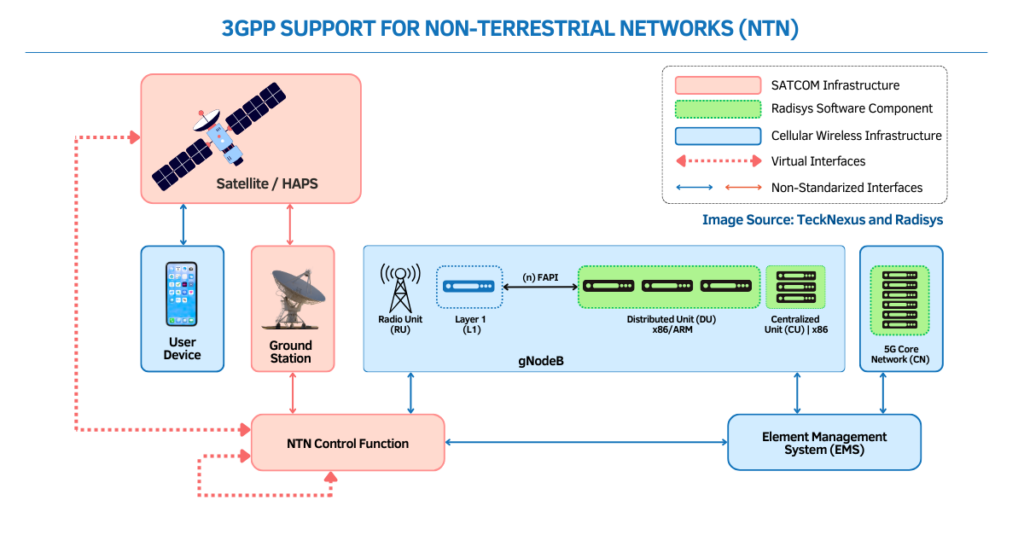
Google AI chips: 4x TPU boost and Anthropic capacity reshape cloud AI
Google has unveiled next‑generation TPU accelerators with up to a 4x performance boost and secured a multiyear Anthropic commitment reportedly worth billions, signaling a new phase in AI infrastructure competition.
TPU performance: 4x speed, higher efficiency, hyperscale scale-out
Google introduced new Tensor Processing Units that deliver roughly four times the performance of prior generations for training and inference of large models. The chips are built for hyperscale clusters on Google Cloud and are tuned for large language models, multimodal workloads, and retrieval-augmented inference. Beyond speed, the design targets better performance-per-watt, a critical lever as AI energy costs surge.

The TPUs integrate with Google’s AI platform stack, including Vertex AI, and support common frameworks via OpenXLA and PyTorch/XLA. That reduces code-porting friction for enterprises that want to diversify beyond GPUs without rewriting models. Google also emphasized fabric bandwidth and cluster scale, two bottlenecks for long-context and Mixture-of-Experts training. In short, the chips aim to cut time-to-train, lower inference latency, and expand capacity for production workloads.
Anthropic deal: committed TPU scale and capital alignment
Anthropic has secured access to Google Cloud TPU capacity at massive scale, with reports citing availability up to one million TPU chips over the term of the agreement. This gives Anthropic a committed runway to train and serve future Claude models while easing supply constraints that have defined the market. The deal deepens an already tight partnership spanning cloud, chips, and product integration.
Separately, Google is in early discussions to increase its financial stake in Anthropic. Options reportedly include a new funding round, a convertible note, or a broader infrastructure-led partnership. Valuation talk of more than $350 billion underscores the premium on foundational model providers with strong revenue trajectories. For Google, aligning compute, platform services, and capital around a flagship model partner is a direct counter to Microsoft’s backing of OpenAI and to Nvidia’s gravity in the AI stack.
Impact on telecom, 5G, and enterprise IT
Faster, more efficient AI silicon and guaranteed capacity change the cost, timing, and risk profile of deploying AI at network and enterprise scale.
AI TCO and energy as board-level constraints
Telecom operators and large enterprises face rising AI electricity bills and supply bottlenecks that delay programs. A 4x performance gain, paired with better performance-per-watt, directly improves total cost of ownership for customer care automation, network planning, and real-time anomaly detection. For use cases like AI-driven call centers or closed-loop assurance in 5G cores, lower inference latency per dollar matters more than raw benchmark wins.
Diversify beyond Nvidia to cut execution risk
The Anthropic agreement signals that at-scale TPU capacity is real and available. For buyers, that creates negotiating leverage and alternative lanes to production. A multi-accelerator strategy spanning TPUs, Nvidia GPUs, and emerging options helps derisk roadmap dependencies. It also allows workload placement based on economics: train on the most cost-efficient pool and serve inference where latency or data residency dictates.
Model choice: Claude, Gemini, and enterprise controls
With Claude on committed TPU scale and Google’s own Gemini models advancing, enterprises gain credible alternatives to OpenAI for regulated and multilingual workloads. That matters for telcos integrating AI into OSS/BSS and care channels where data sovereignty, safety guardrails, and predictable SLAs are mandatory. Running models through Vertex AI with regionally pinned data and enterprise controls can simplify compliance across markets.
AI stack competition and standardization
The move sharpens the fault lines among hyperscalers and chip ecosystems while pushing software standardization up the stack.
Cloud and silicon strategies converge
Microsoft pairs Azure with OpenAI and a deep Nvidia roadmap. Google counters with TPU acceleration, Gemini, and Anthropic scale. Amazon advances Trainium/Inferentia while courting model providers on Bedrock. Add AMD’s MI300-class accelerators and Intel’s Gaudi line, and buyers have real choice for both training and inference. The practical question is no longer “which is faster,” but “which stack delivers the best dollars-per-token and SLA for my workload.”
Software portability will determine winners
OpenXLA, PyTorch/XLA, JAX, and Kubernetes-native MLOps are critical to reduce switching costs. Enterprises should insist on containerized deployments, model server abstractions (such as KServe), and standardized observability. Without this, moving between TPU, GPU, and custom accelerators becomes a rewrite project instead of a redeploy.
Networking and data pipelines as bottlenecks
Training efficiency now hinges on interconnect bandwidth, storage throughput, and data orchestration. As clusters scale, 400G/800G Ethernet fabrics, optical interconnects, and advanced schedulers determine utilization. For telcos building AI-capable data centers or edge sites, investing in high-throughput fabrics and feature stores will yield bigger gains than chasing peak TOPS on paper.
Strategic next steps for telecoms and enterprises
Leaders should translate these announcements into concrete procurement, architecture, and pilot decisions over the next two quarters.
Adopt multi-cloud, multi-accelerator sourcing
Negotiate reserved capacity on at least two stacks across TPU and GPU options to hedge supply and price volatility. Build portability into contracts, including exit rights, data egress concessions, and workload migration support.
Prioritize high-ROI inference
Start with call center copilots, collections, network trouble-ticket summarization, and proactive outage communications—areas with measurable KPIs. For RAN optimization and traffic engineering, consider hybrid designs that blend small domain models at the edge with centralized large models for planning.
Benchmark economics to real outcomes
Evaluate chips and clouds by cost per million tokens, latency at p95, and energy per query, not just peak FLOPS. Use independent benchmarks where available and run your own canary tests with production data distributions. Tie contracts to SLOs across throughput, uptime, and data residency.
Strengthen governance and safety before scale
Standardize prompt injection defenses, content filtering, red-teaming, and audit trails across all providers. Align on model cards, evaluation protocols, and incident response so that switching models or accelerators does not reset your compliance posture.
Prepare data pipelines, not just chips
Invest in data quality, vectorization pipelines, and retrieval layers. Clean, well-instrumented data paired with robust feature and embedding stores will unlock more value from any accelerator—TPU or GPU—than chasing the latest spec alone.
The bottom line: Google’s 4x TPU jump and the Anthropic capacity-and-capital alignment raise the bar on price-performance and availability for foundation model workloads. Telcos and enterprises that architect for portability, measure economics rigorously, and prioritize near-term, high-ROI use cases will convert this market shift into durable advantage.