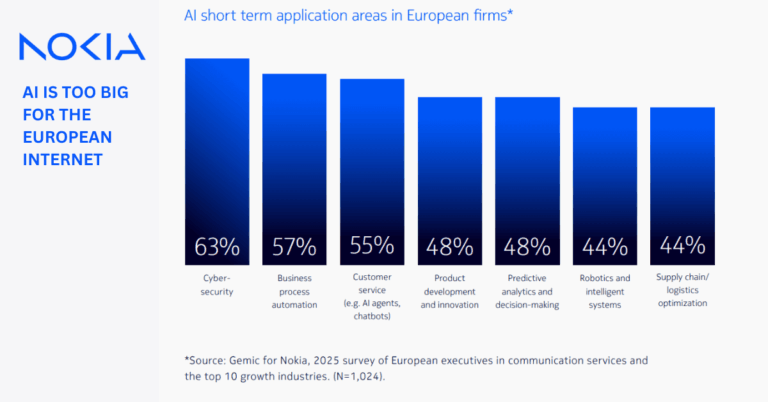
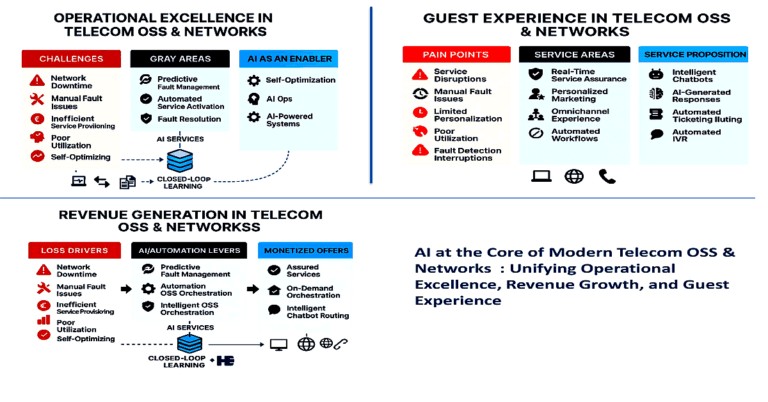
SK hynix HBM4 sets new baseline for AI accelerators and data centers
SK hynix says it has completed development and readied mass production of HBM4, signaling a new performance and efficiency baseline for next‑generation AI accelerators and cloud infrastructure.
HBM4 specs: 2,048‑bit I/O, >10 Gbps, and 40% efficiency gains
HBM4 doubles per‑stack bandwidth versus the prior generation by moving to a 2,048‑bit I/O interface and pushing data rates beyond 10 Gbps per pin, exceeding the JEDEC baseline of 8 Gbps for this class of memory. The company also cites more than 40% improvement in power efficiency, a critical lever as AI clusters strain data center power envelopes. Taken together, SK hynix claims this can lift end‑to‑end AI service performance by up to roughly two‑thirds depending on workload and system balance. For buyers, this is not just a faster memory stack: it is a path to higher utilization on expensive accelerators, fewer memory‑bound stalls, and better performance per watt.

HBM4 manufacturing: MR‑MUF packaging and 1bnm DRAM for yield
To de‑risk ramp, SK hynix is leaning on a mature advanced packaging flow (its advanced MR‑MUF molded underfill) and its 1bnm DRAM process node, the fifth generation of its 10‑nanometer‑class technology. MR‑MUF, which fills and cures material between stacked dies, improves warpage control and heat dissipation—two chronic issues when stacking many DRAM dies with through‑silicon vias. The combination aims to stabilize yields at high stacks and frequencies, which historically has been the gating factor for HBM scale, not just the memory die design itself.
System impact: faster training, inference, and performance per watt
HBM4’s bandwidth increase directly attacks AI training and inference bottlenecks in transformer models, graph workloads, and memory‑intensive vector search. The power efficiency uplift helps operators hold rack density targets without blowing through power caps as GPU/accelerator thermal design points continue to rise. Expect improvements in time‑to‑train, tokens‑per‑second, and memory capacity bandwidth ratios per accelerator, translating into lower cost per model run and more predictable latency under load.
HBM4 competition: Nvidia Rubin alignment, Samsung and Micron progress
Being first to declare HBM4 mass‑production readiness is as much a supply‑chain signal as a technology milestone, with direct consequences for accelerator launches and procurement strategy through 2026.
Nvidia Rubin memory plan: HBM4 pairing and SK hynix share outlook
Market watchers widely expect HBM4 to be the primary memory pairing for Nvidia’s next‑generation Rubin architecture for data centers. SK hynix is already a key HBM supplier to Nvidia, and this timing suggests it is well placed for early Rubin ramps. Rivals are advancing—Micron has shipped HBM4 samples and Samsung is working through large‑customer qualifications—but analysts still project SK hynix to hold a commanding HBM share into 2026, potentially near the half‑market mark. Investor reaction echoed that read, with SK hynix shares jumping on the announcement and HBM‑driven revenues now representing roughly three‑quarters of the company’s mix in recent quarters.
Supply risk: TSV stacking and advanced packaging capacity
For buyers, the key risk is less about whether HBM4 works and more about who can ship volume through 2026. Capacity is constrained by advanced packaging steps: TSV‑based stacking, micro‑bump, underfill, and 2.5D interposer assembly. Even with multiple OSATs and foundry partners expanding, meaningful supply elasticity takes quarters, not weeks. Multisourcing remains prudent, but cross‑vendor HBM4 equivalence will vary by speed bins, stack heights, and thermal characteristics. Early allocations will favor accelerator vendors with locked‑in forecasts and proven ramp discipline.
HBM4 standards: JEDEC, signal integrity, and power delivery
HBM4 sits within JEDEC’s framework, but controller implementations, signal integrity at higher speeds, and power delivery nuances differ across accelerators and board designs. SK hynix’s >10 Gbps operating point is notable, yet sustained operation at those speeds depends on interposer design, channel loss budgets, and packaging thermals. Expect vendors to qualify multiple bins; architects should map platform requirements to specific speed grades rather than assuming uniform HBM4 behavior.
Design priorities for HBM4‑based AI systems
As HBM4 enters the BOM, system designers must rebalance memory bandwidth, capacity, thermals, and cost across training and inference fleets.
Balance compute with HBM4 bandwidth for AI workloads
Next‑gen accelerators will offer more FLOPS and potentially larger on‑package SRAM, but memory wall effects persist without proportional HBM bandwidth growth. HBM4’s doubled interface width and higher per‑pin rate help restore balance, enabling higher batch sizes or sequence lengths without thrashing. Plan for configuration variants—different stack heights and capacities—to optimize for training versus latency‑sensitive inference, and validate scaling efficiency at target sequence lengths and KV‑cache footprints.
HBM4 thermals: liquid cooling and rack‑level power planning
A 40% efficiency gain at the memory stack level does not erase rising platform TDPs. Liquid cooling, higher‑capacity cold plates, and improved airflow management remain necessary to sustain HBM4 speed bins and avoid throttling. Revisit rack‑level power models, PDU provisioning, and aisle‑level heat extraction; the right metric is useful tokens per kilowatt‑hour, not component‑level watts. Facilities teams should budget for incremental density and thermal headroom aligned to 2025–2026 accelerator refreshes.
HBM4 reliability: TSV integrity, underfill quality, and RAS
Advanced MR‑MUF and mature nodes reduce warpage and mechanical stress, but stacked DRAM reliability still hinges on TSV integrity, underfill quality, and package‑to‑interposer joints under thermal cycling. Push vendors for detailed RAS data—error rates under maximum bandwidth, soft‑error mitigation, sparing, and field‑return statistics. Ensure your qualification includes burn‑in at peak temperature, vibration testing for sled moves, and telemetry hooks to isolate memory‑induced performance drops.
Next steps and key signals for HBM4 adoption
With HBM4 poised to anchor the next wave of AI systems, procurement and architecture teams should lock designs and allocations early while monitoring key execution signals.
Monitor Rubin timing, HBM4 yield bins, JEDEC updates, OEM roadmaps
Track Nvidia’s Rubin launch cadence and memory configurations, SK hynix’s yield and speed‑bin distributions, and the timing of Samsung and Micron customer qualifications. Watch JEDEC updates that may influence interoperability and power targets, and look for server OEM disclosures on HBM4‑based systems across major vendors. Shipment lead times for advanced packaging and interposers will be the leading indicator of practical capacity.
Act now: secure allocations, qualify vendors, validate cooling and TCO
Align 2025–2026 AI cluster plans to HBM4‑equipped accelerators and refresh TCO models using realistic speed bins and thermal limits. Secure multi‑quarter memory allocations in tandem with accelerator commits, and pre‑qualify at least two HBM4 sources where feasible. Run application‑level benchmarks to verify gains at target sequence lengths and KV‑cache sizes, and validate liquid cooling or hybrid solutions necessary to sustain HBM4 performance. Finally, update power and sustainability roadmaps—memory efficiency gains can translate to meaningful energy savings at fleet scale if captured in scheduling and capacity planning.