AI in Production for Virgin Media O2 with Zinworks for Mobile Network Assurance
Virgin Media O2 is expanding its use of AI from fixed broadband into mobile, signaling a pragmatic shift toward predictive, automated network operations at national scale.
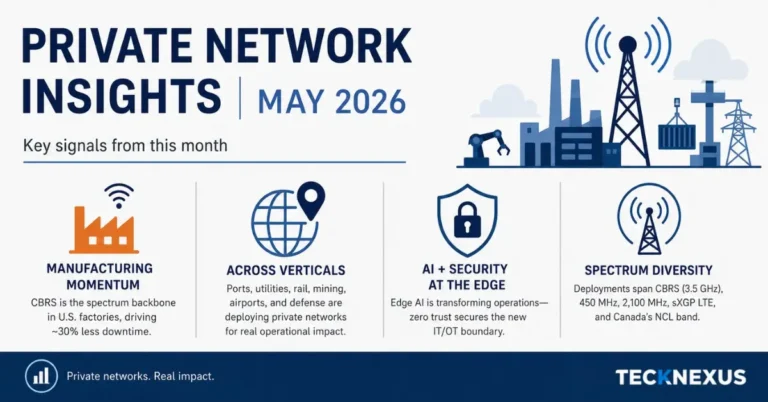
AI monitoring and automation rollout
Virgin Media O2 has broadened its partnership with Zinkworks to deploy AI-driven monitoring and automation across its mobile footprint, designed to spot anomalies earlier, resolve incidents faster, and prevent customer-impacting outages. The rollout targets multiple network domains and operational workflows, advancing the operator’s move toward autonomous operations with engineers maintaining full oversight.
AI coverage across RAN, core, and NOC
The capabilities span radio access, core network systems, and network operations centers, combining real-time telemetry with intelligent automation. The stack runs on Google Cloud and taps services such as Vertex AI and Gemini to analyze patterns, orchestrate responses, and augment decision-making for operations teams. The goal is higher reliability during traffic spikes and better service consistency across the UK.
Fixed broadband results: 33% faster repair and 12% fewer visits
The operator is building on two years of AI-enabled assurance in its fixed broadband estate, where it cut time-to-repair by over a third and reduced the need for engineer visits by roughly 12%. Those operational wins now inform the mobile playbook, with a focus on preventing issues before they escalate.
Why AI-led assurance matters for 5G and uptime
AI-led service assurance is becoming essential as cloud-native 5G, edge workloads, and escalating customer expectations raise the bar for uptime and performance.
5G complexity and near-zero downtime expectations
5G standalone cores, containerized network functions, and dense RAN deployments create more moving parts and failure modes. At the same time, consumer and enterprise customers expect consistent experience during events, software upgrades, and seasonal peaks. Manual and reactive operations cannot scale to this new normal.
Shift to AIOps and closed-loop autonomous operations
The shift is toward AIOps and closed-loop automation that forecasts degradation, prescribes fixes, and executes changes before users notice. Eliminating minutes from mean time to detect and mean time to restore can protect revenue, SLAs, and brand equity. This announcement shows those principles moving into day-to-day mobile operations, not just labs and proofs of concept.
How AI-enabled, closed-loop network assurance works for Virgin Mobile O2
Under the hood, the solution fuses broad observability with machine learning and policy-driven automation to create closed-loop operations with a human-in-the-loop.
Real-time telemetry and cross-domain observability fabric
Streaming telemetry, KPIs and KQIs, logs, traces, and alarms feed a real-time data plane. Cross-domain views correlate RAN, transport, and core events to pinpoint root causes and forecast hotspots. Quality and timeliness of telemetry are as critical as the models.
Anomaly detection, forecasting, and policy-driven closed loops
Anomaly detection and time-series forecasting identify deviations and impending faults. Playbooks translate insights into actions, such as RAN parameter tuning, traffic steering, or scaling cloud-native network functions. Engineers remain in control, approving changes or setting guardrails for fully automated responses in low-risk scenarios.
Google Cloud, Vertex AI, and Gemini for network AIOps
Google Cloud underpins the analytics and automation stack, while Vertex AI and Gemini support model training, inference, and AI assistants for operations. Generative AI can augment triage, summarize incidents, and standardize ticket narratives, cutting cognitive load in the NOC and speeding collaboration.
Strategic implications for operators and vendors
The deployment signals a maturing market for autonomous operations and raises the competitive bar for service reliability and cost efficiency.
Reliability and proactive assurance as competitive advantage
Proactive assurance can improve customer experience during high-demand windows and reduce churn. For B2B, fewer incidents and faster restoration strengthen SLAs and open doors for premium services and network slicing as they scale.
NetOps to SRE with MLOps and policy automation
NetOps evolves toward SRE-style practices with software-first troubleshooting, policy automation, and continuous improvement cycles. Upskilling in data engineering, MLOps, and intent-driven orchestration becomes a board-level priority for operators and their partners.
Interoperability aligned with ETSI ZSM and TM Forum
Interoperability matters as automation spans vendors and domains. While not specific to this deal, architectures that align with industry efforts such as ETSI Zero-touch network and Service Management and TM Forum’s Autonomous Networks framework help avoid lock-in and ease multi-vendor integration over time.
Risks, challenges, and governance for trustworthy autonomy
Delivering trustworthy autonomy at scale depends on disciplined data management, integration, and accountability.
Data quality, telemetry gaps, and model drift management
Incomplete or noisy telemetry leads to false positives or missed faults. Continuous validation, retraining, and version control are required to keep models accurate as networks evolve.
Integrating closed loops with legacy OSS/BSS
Closed-loop actions must coordinate with existing OSS/BSS, change windows, and vendor-specific interfaces. Without robust APIs and testing, automation can create new failure modes as fast as it removes old ones.
Human-in-the-loop guardrails, audit, and rollback
Human-in-the-loop guardrails, audit trails, and rollback mechanisms are essential, especially when automating actions that affect live traffic. Clear RACI models and incident postmortems keep accountability intact.
Next steps and roadmap for AI-led network assurance
Leaders should translate this momentum into concrete roadmaps that blend quick wins with foundational capabilities.
For operators: quick wins and foundational capabilities
Start with high-value, low-risk closed loops such as anomaly-driven capacity adjustments or automated ticket enrichment. Invest in a unified observability pipeline to normalize RAN, core, and cloud telemetry. Build an MLOps capability for model governance, testing, and safe rollout. Define automation guardrails and intent policies jointly across engineering, operations, and security. Measure outcomes in MTTR, customer impact minutes, and truck-roll avoidance to fund the next wave.
For buyers and partners: SLA and transparency expectations
Ask providers how predictive assurance protects your services during peak periods and planned changes. Seek transparency on incident detection, escalation, and resolution timelines. Where possible, link service tiers to proactive monitoring capabilities and energy-efficient operations to support sustainability targets.
What to watch through 2025: autonomy milestones
Expect steady movement from predictive insights to policy-driven, autonomous execution across more of the mobile stack.
From detection to automated remediation milestones
Look for expansion from detection to automated remediation in additional domains, plus published metrics on outage avoidance and time saved. Independent benchmarks and regulator engagement will validate progress.
GenAI copilots for NOC triage and knowledge management
Broader use of AI assistants to summarize incidents, recommend playbooks, and standardize knowledge bases should cut toil and speed onboarding of new engineers.
Assurance linked to SLAs and energy-aware optimization
Expect tighter coupling between proactive assurance, enterprise SLAs, and energy-aware optimization as operators balance performance, cost, and carbon goals.