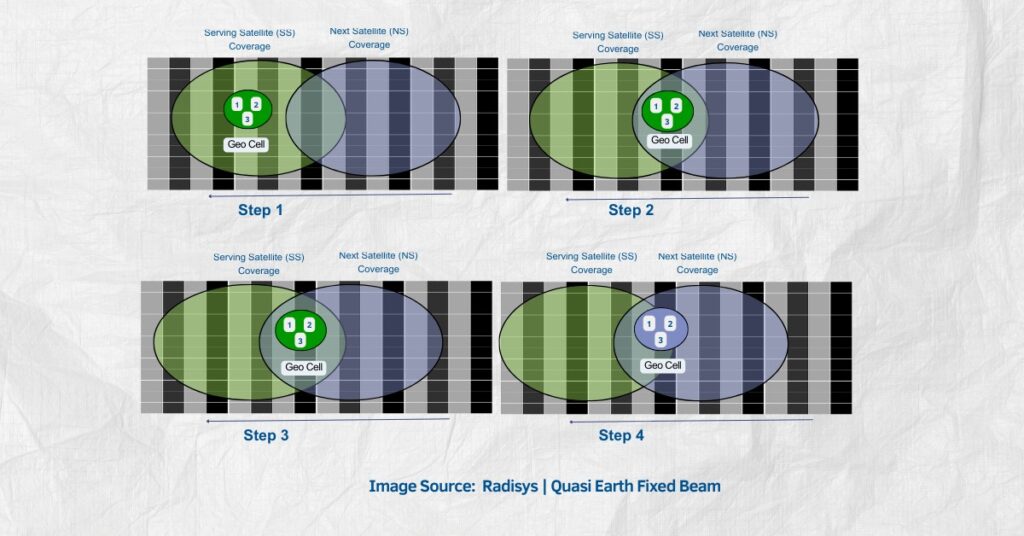
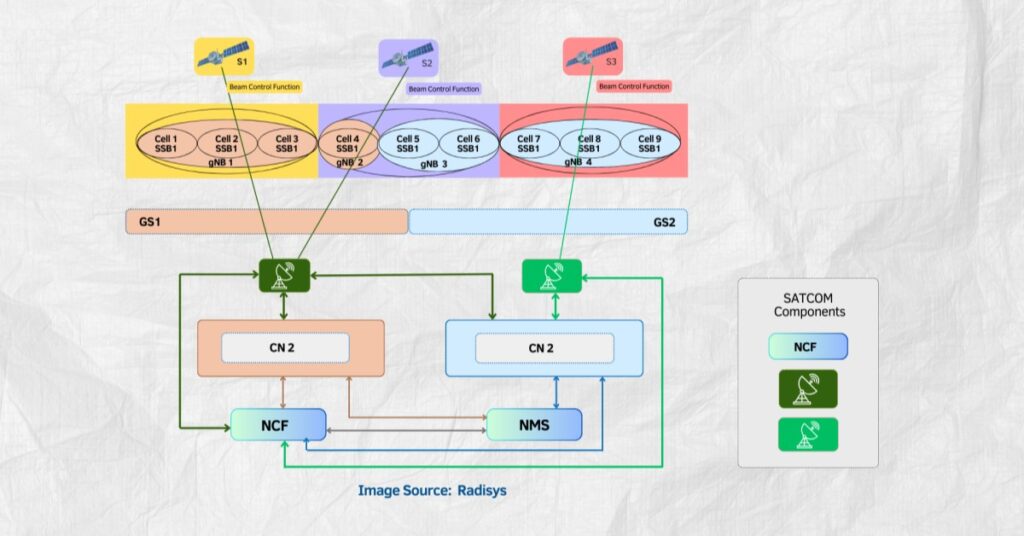
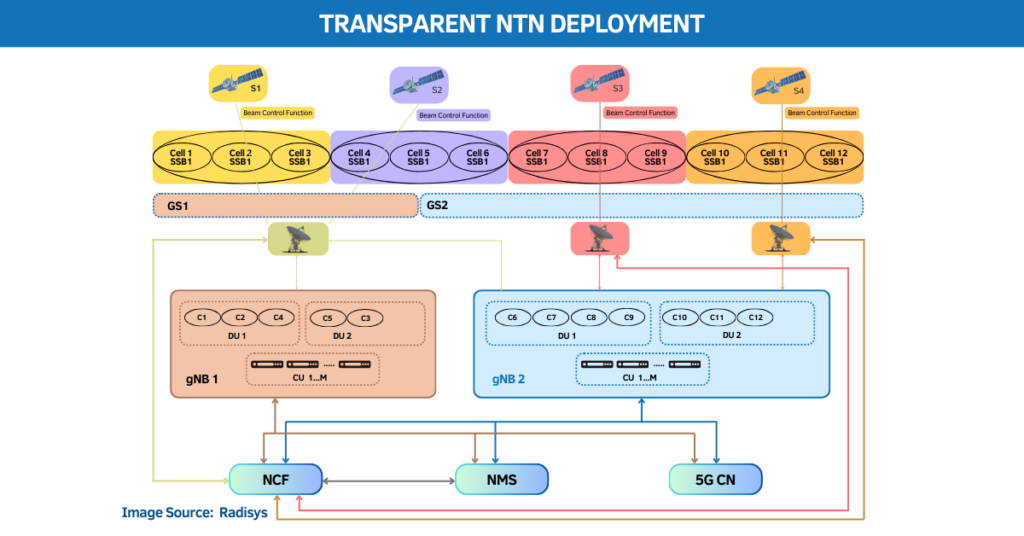
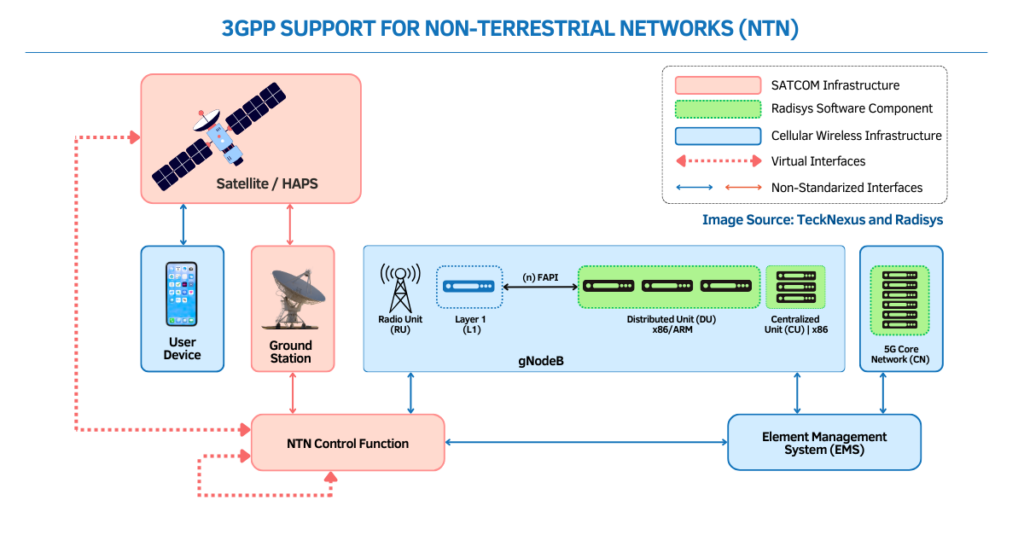
Nvidia earnings reset the AI infrastructure baseline
Nvidia’s latest quarter signals that AI infrastructure spending is not cooling and is, in fact, broadening across clouds, sovereigns, and enterprises.
Data center revenue drives growth
Nvidia delivered $57 billion in revenue for the quarter, up more than 60% year over year, with GAAP net income reaching $32 billion; the data center segment accounted for roughly $51.2 billion, dwarfing gaming, pro visualization, and automotive combined.

This scale makes Nvidia the de facto operating system for AI data centers: it now commands the overwhelming share of AI accelerators while bundling GPUs with high-speed interconnects, networking, systems, and software to remove integration friction.
Outlook: AI GPU demand exceeds supply
Management guided next-quarter sales to about $65 billion, exceeding consensus by several billion and underscoring that supply remains tight for cloud GPUs even as deployments ramp across hyperscalers, GPU clouds, national AI initiatives, and large enterprises.
Importantly, the company flagged an aggregate of roughly five million GPUs tied to announced AI factory and infrastructure projects, a strong forward indicator for both training and inference capacity coming online through 2026.
AI surge drivers: AI factories, Blackwell, inference at scale
The mix has shifted from experimentation to industrialized AI, with newer architectures and use cases compounding demand.
From pilots to repeatable AI factories
Customers are standardizing on repeatable AI build-outs—spanning model training, fine-tuning, and high-throughput inference—rather than one-off clusters; these projects are showing up across cloud service providers (CSPs), sovereign AI programs, modern digital builders, and supercomputing centers.
Blackwell leads across cloud providers
Nvidia’s Blackwell generation, including Blackwell Ultra configurations, has become the company’s flagship in the field, with prior-generation accelerators still seeing healthy pull-through; cloud instances are heavily subscribed, reflecting the preference for the latest silicon where power and memory bandwidth translate directly into throughput and lower unit cost of compute.
Training and inference spending both compounding
Where last year’s spending concentrated on training frontier and domain models, this year the wallet is splitting: training remains heavy, but inference is now scaling quickly as enterprises deploy assistants, search augmentation, and agentic applications into production.
Risks: China export limits, geopolitics, circular deals
While top-line momentum is exceptional, a few structural risks bear watching.
Export controls curtail China accelerator sales
U.S. restrictions on advanced accelerator shipments have curbed Nvidia’s ability to sell competitive data center GPUs into China, and management is not counting on material China AI accelerator revenue near term; alternative, lower-spec SKUs have struggled to gain traction amid policy uncertainty and local competition.
Startup tie-ups raise governance and concentration risks
Large, multi-party arrangements—such as investments alongside hyperscalers in model providers like Anthropic or engagement with OpenAI—can create the appearance of circular demand, where equity, cloud commitments, and compute purchases intersect; Nvidia argues these positions are strategic, extend its ecosystem, and can yield financial returns, but boards should scrutinize counterparty risk and concentration.
Competitive landscape: AMD, custom silicon, GPU clouds
Rivals see an opening, yet Nvidia’s integration advantage remains a high bar.
AMD accelerators and custom silicon gain traction
AMD projects rapid growth for its AI accelerator line, and major operators are widening bets on custom silicon with vendors such as Broadcom and Qualcomm, while hyperscalers continue to refine in-house designs; GPU cloud specialists like CoreWeave and Nebius are also expanding to capture demand spillover.
Nvidia’s full-stack moat: software, systems, networking
Beyond chips, Nvidia’s moat includes software (CUDA, libraries, compilers), tools for model training and inference optimization, and tightly coupled systems and networking—reducing time-to-productive compute; customers that trial alternatives often revert due to ecosystem maturity, performance per watt, and integration speed.
Implications for telecom, cloud, and enterprise IT
The AI capex wave is reshaping data center design, network architectures, and workload placement strategies across the stack.
AI network and data center design implications
High-radix, low-latency fabrics and lossless transport are moving from niche to standard in AI clusters, pushing operators toward specialized interconnects, AI-optimized Ethernet, and advanced congestion control; power density, liquid cooling, and optical interconnect upgrades are now gating factors for build velocity.
Workload placement: cloud GPUs vs on‑prem AI factories
With cloud GPUs heavily subscribed, many enterprises are adopting a hybrid approach—reserving cloud for elasticity and model experimentation while standing up on-prem or colocation “AI factories” for steady-state training and high-throughput inference; telcos and edge providers can monetize proximity for latency-sensitive inference and video analytics.
Budgeting for AI: TCO and tokens per joule
Procurement must evaluate total cost of results, not list price per GPU: include utilization, software maturity, model efficiency, interconnect performance, and power; the cheapest path is often the configuration that maximizes tokens per joule at target accuracy.
What to watch next and immediate actions
Execution, policy, and ecosystem moves over the next two quarters will set the pace for 2026 deployments.
Key signals to monitor
Track Blackwell production ramps and lead times, hyperscaler capex outlooks, sovereign AI awards, U.S.–China export policy shifts, and the share of spend shifting from training to inference; also watch competitive benchmarks from AMD and early results from custom accelerators in production-scale workloads.
Immediate actions for CTOs and architects
Secure multi-year capacity with diversification across cloud GPU providers and colocation partners; design AI networks up front with headroom for east–west traffic and plan for liquid cooling retrofits; build a portability layer to hedge across Nvidia and non-Nvidia backends; standardize an inference platform with aggressive quantization and compilation to lower cost per query; and institute governance for AI partnership structures to avoid concentration and “circular” commitments.
Bottom line: Nvidia’s results validate that AI infrastructure is transitioning from hype to utility, and operators that align capex, networking, and software around this reality will capture outsized returns as inference at scale becomes a core workload.