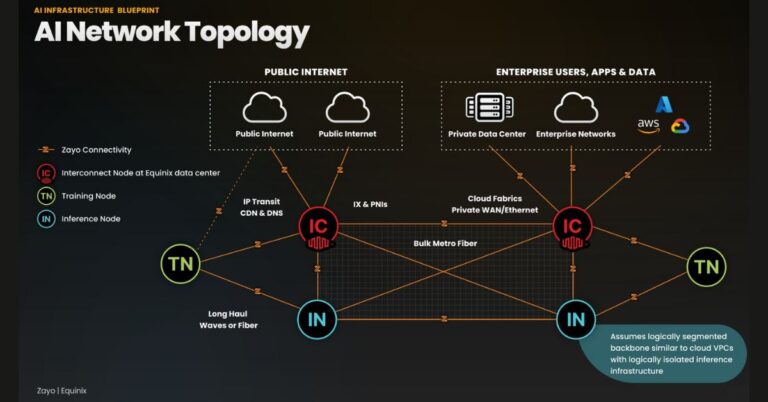
Why the Zayo–Equinix AI Blueprint Sets a Network-First Standard
AI now depends as much on the network and interconnection layer as it does on GPUs, and this blueprint turns that reality into a repeatable design.
Closing the AI Scale Gap: Network Design for Training and Edge Inference
Training has concentrated in a few massive regions, while inference is exploding at the edge and in enterprise colocation sites, creating a scale challenge the industry hasn’t codified—until now. Zayo and Equinix are proposing a common model that aligns high-capacity transport, neutral interconnection hubs, and specialized training and inference data centers. The aim is to shorten time to market for AI services by providing reference designs that reduce trial-and-error across L1–L3, interconnection, and traffic engineering. With AI-driven bandwidth expected to multiply severalfold by 2030, the winners will be those who design networks that scale before demand lands.

Data Gravity and Latency Budgets for Edge AI Inference
Generative AI is pushing enterprises to place data stores, vector indexes, and model gateways near users and applications. That shifts the bottleneck from compute to movement and synchronization of data across regions and partners. Low-latency inference requires deterministic paths, proximity to interconnect exchanges, and predictable egress between clouds, neoclouds, and enterprise sites. A blueprint that standardizes where to place interconnection nodes, how to segment training versus inference traffic, and when to use private routing versus public paths is timely and actionable.
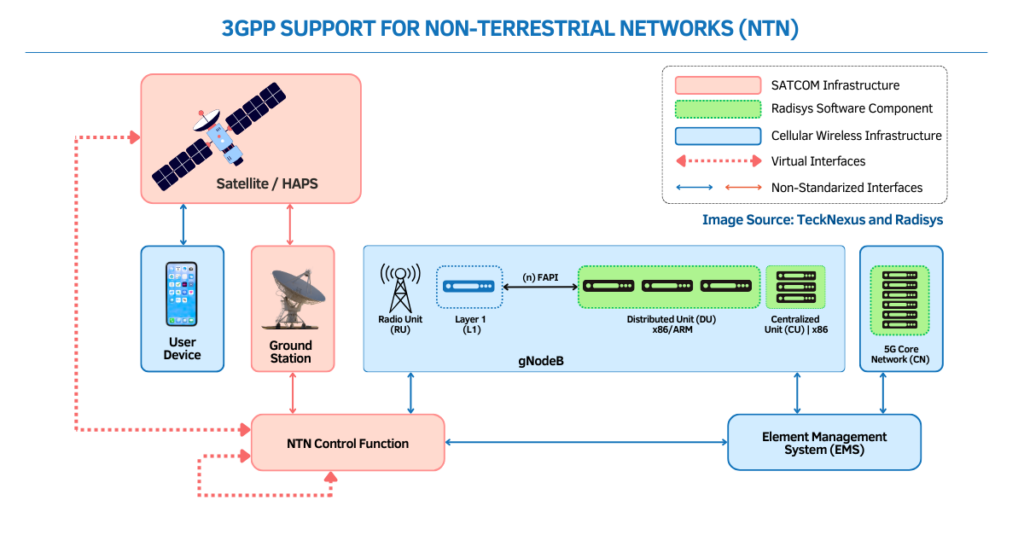
Inside the AI Blueprint: Roles, Network Layers, and Proven Patterns
The framework clarifies who does what in a distributed AI stack and how to connect it with proven network patterns.
Interconnection Hubs as the Control Plane for AI Traffic
Equinix acts as neutral meet-me points where clouds, neoclouds, carriers, and enterprises exchange traffic and stitch private circuits. With 270-plus interconnection hubs globally, the design centers on placing AI training and inference infrastructure adjacent to these hubs to minimize cross-domain latency and enable multi-cloud, multi-network routing without tromboning traffic back to origin regions. This is where IP peering, cloud on-ramps, and data exchange policies converge.
400G/800G Backbone and Metro Fiber for AI-Scale Data Movement
Zayo provides the long-haul and metro capacity to move petabytes between training regions, data sources, and inference edges. The blueprint leans on dense metro footprints for east–west flows and long-haul routes for region-to-region synchronization, with an emphasis on 400G/800G-ready transport, optical diversity, and path protection. Zayo has committed to thousands of new route miles of long-haul builds and is expanding metro reach through acquisitions to meet AI-era bandwidth growth.
SDN-Orchestrated Connectivity and Intelligent Interconnect Fabric
Interconnection is increasingly software-defined. The design prescribes SDN-based provisioning for private connectivity, with Equinix Fabric used to automate discovery, activation, and optimization across partners. Added intelligence helps right-size bandwidth for bursty training epochs, prioritize inference latency, and steer flows based on policy, cost, and data residency. Expect integration with cloud routers, EVPN/VXLAN overlays, segment routing, and line-rate encryption to become table stakes.
Reference Designs and a Shared Vocabulary for AI Networking
The value is not only in products but in a common language that spans training clusters, feature stores, inference gateways, and the network layers that bind them. The blueprint codifies design patterns informed by decades of IP peering and cloud connectivity—where to terminate routes, how to align QoS with workload classes (checkpointing vs. inference RPC vs. retrieval), and when to use private versus public peering. This reduces integration risk and creates repeatability across geographies and partners.
Strategy: Pairing Neutral Interconnection with Scalable Fiber
The partnership pairs Equinix’s neutral exchange model with Zayo’s fiber buildout to operationalize distributed AI at scale.
Capacity Bets: Long-Haul Builds and Metro Densification for AI
Zayo is scaling transport capacity to meet AI data flows by adding new long-haul routes and growing metro fiber depth. Its planned acquisition of a large metro fiber business adds well over 100,000 route miles in cities—critical for last-mile diversity, feeder routes into AI clusters, and private connectivity to enterprise campuses. This underpins the blueprint’s promise of predictable, high-throughput paths between training sites, data lakes, and inference edges.
Equinix’s Distributed AI Strategy and Fabric Intelligence
Equinix is complementing the blueprint with a distributed AI strategy that includes an AI-ready backbone, a global lab to validate solutions with partners, and fabric-level intelligence to make interconnection adaptive. Together, these moves target the practical blockers to AI rollout: integration complexity, latency unpredictability, and the need to scale across multiple clouds and providers without lock-in.
What the AI Blueprint Means for Providers and Enterprises
The framework is a signal to align architectures, contracts, and KPIs around a network-first AI operating model.
Guidance for Neoclouds and AI-Native Providers
Blueprint-aligned designs can accelerate region turn-ups and improve gross margins by minimizing egress and backhaul. Position training near data sources or interconnect hubs, keep inference close to user clusters, and use private routing to meet SLAs. Standardizing on EVPN overlays, PTP time sync, and loss-minimized paths for GPU-to-GPU flows will be essential as clusters span multiple facilities.
Guidance for Carriers and Wholesale Network Partners
The model sharpens demand signals for 400G/800G waves, dark fiber, and metro rings with strict jitter and availability targets. Partners that bring diverse routes into Equinix campuses and offer API-driven provisioning will gain wallet share as AI providers seek fast, automated turn-up across markets.
Guidance for Enterprises Operationalizing AI
The takeaway is to treat interconnection as part of the AI stack. Use neutral hubs to connect data estates, vector databases, and model endpoints across clouds with private, policy-driven paths. Separate training, retrieval, and inference traffic classes with distinct latency and bandwidth budgets, and place inference gateways in metros where users and applications reside to cut response times and egress costs.
Next Steps: Turning the AI Blueprint into Action
Network, cloud, and data leaders should translate the blueprint into a concrete rollout plan and measurable KPIs.
Architect Distributed Training-to-Inference Paths
Map data sources, training regions, and target inference metros; locate interconnection hubs on that map; and design private routes that avoid hairpins. Use the hubs to enforce data residency and routing policies across clouds and partners.
Engineer Networks for AI KPIs: Latency, Jitter, Loss, Throughput
Set explicit budgets for latency, jitter, packet loss, and throughput by workload type. Design for 400G/800G scalability, diverse paths, MACsec or optical encryption, and PTP time synchronization where required. Validate with synthetic inference and checkpointing tests before production.
De-Risk with Neutral Interconnection Hubs and Multi-Vendor Fabrics
Adopt interconnection fabrics that support real-time discovery and activation, and negotiate cross-connect SLAs that match AI workload profiles. Keep optionality with multiple carriers, clouds, and neocloud providers at each hub.
Plan Contracts and Capacity Through 2030
Given multi-x bandwidth growth trajectories, align long-haul and metro capacity reservations with GPU cluster roadmaps, and build playbooks for rapid metro expansions near user demand. Use the blueprint’s reference designs to standardize deployments across regions and partners.