Executive Summary: GPU AI-RAN Validates 16-Layer MU-MIMO
SoftBank and NVIDIA have validated a fully software-defined, GPU-accelerated AI–RAN that delivers 16-layer massive MU-MIMO outdoors—an inflection point for vRAN performance, Open RAN scalability, and AI-native RAN design.
Field Demo: Full L1 on GPUs with 16-Layer MU-MIMO
SoftBank’s AI-RAN product, AITRAS, executed the entire 5G physical layer on NVIDIA GPUs at the Distributed Unit and demonstrated stable 16-layer multi-user MIMO downlink in an outdoor trial at NVIDIA’s Santa Clara campus. The system connected to O-RAN-compliant radios via Split 7.2x and achieved roughly three times the spectral efficiency and throughput of a conventional 4-layer setup while maintaining per-user rates under high load.

Why It Matters for vRAN, Open RAN, and 5G-Advanced
vRAN and Open RAN have been held back by Layer 1 performance, determinism, and energy constraints; proving a high-order massive MIMO stack running purely on GPUs under real-world timing budgets moves AI-native RAN from lab promise to field-ready reality as operators plan 5G-Advanced rollouts and 6G trajectories.
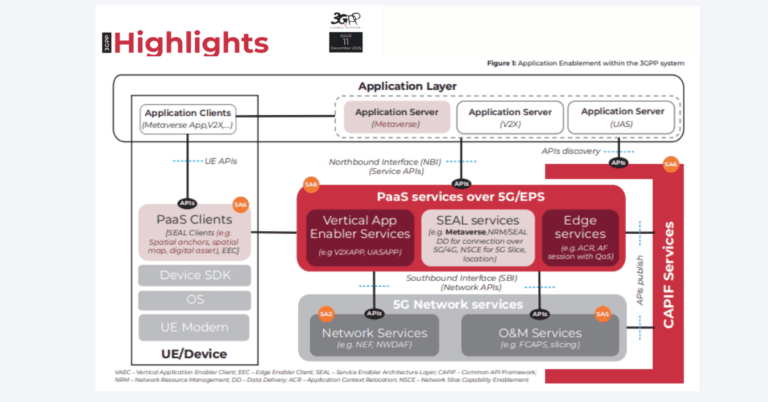
Inside SoftBank’s GPU-Powered AI-RAN Architecture
The design pairs standards-based O-RAN fronthaul with CUDA-accelerated signal processing and AI inference co-located at the DU for coordinated control across radios.
Full L1 on GPU at the DU with CUDA Acceleration
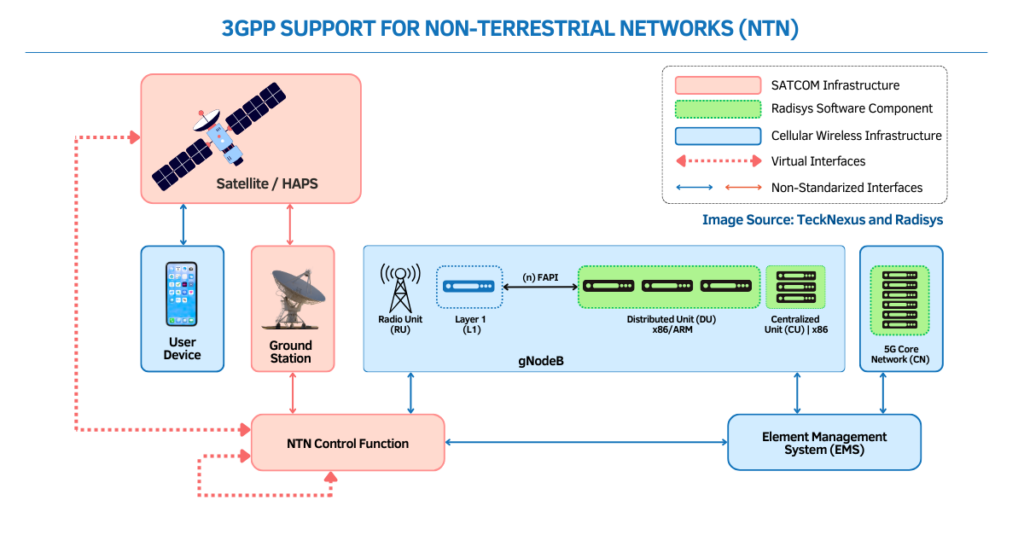
AITRAS implements baseband Layer 1 entirely in software on GPUs using large-scale CUDA parallelism, replacing traditional FPGA or ASIC accelerators. Massive MIMO matrix math, channel estimation and equalization, precoding, and beamforming run on general-purpose hardware, enabling rapid iteration and software feature velocity while meeting RAN timing constraints.
Standards: 3GPP Compliance and O-RAN Split 7.2x
The DU interfaces with general-purpose O-RUs using O-RAN Split 7.2x, preserving multi-vendor openness. Unlike approaches that offload uplink estimation to the radio, AITRAS keeps the full workload in the DU to avoid adding proprietary functions to O-RUs and to consolidate compute for coordination across cells.
AI in the PHY Signal Chain and Coordinated Control
By aggregating uplink signals from multiple O-RUs into a GPU-powered DU, AITRAS enables AI-based coordinated control to improve radio quality and capacity. Techniques include uplink channel interpolation—inferring full channel state from sparse DMRS observations—and more precise beamforming that can be extended toward higher-order or cell-free MIMO in future releases.
Outdoor Trial Results and Performance Gains
The field results show that software-only massive MIMO on GPUs can meet macro-radio conditions without bespoke silicon.
16-Layer MU-MIMO Validated in Outdoor Macro
Achieving 16-layer downlink MU-MIMO in a live outdoor environment confirms that the GPU-based DU can deliver high-order spatial multiplexing with tight latency and synchronization, not just in controlled labs. This closes a key credibility gap for software-defined RAN performance at scale.
Capacity Gains and Per-User Experience
Relative to 4-layer baselines, the trial reported approximately threefold gains in spectral efficiency and cell throughput, with stable per-user performance even during congestion. That translates directly into higher site capacity, better cost-per-bit, and more headroom for 5G-Advanced features like enhanced MIMO and traffic steering.
Strategic Impact for Operators and Vendors
The shift concentrates value in accelerated computing and software while simplifying radios and enabling AI to shape RAN behavior in near real time.
Shift to Software-Defined RAN and DU Pooling
Running L1 entirely in software reduces dependence on custom silicon roadmaps and allows operators to evolve features through software releases. It supports DU pooling, faster innovation cycles, and programmable optimization of beams, scheduling, and interference management aligned with 3GPP evolution.
NVIDIA’s Role in RAN and Ecosystem Signals
The demonstration highlights NVIDIA’s growing role in telecom as GPU acceleration moves into the RAN data plane, not just AI inference or analytics. As operators evaluate vRAN options, a software-first massive MIMO path favors hyperscale-style supply chains and could tilt budgets toward accelerated compute and CUDA-based RAN frameworks, while keeping O-RUs commodity and O-RAN friendly.
Challenges, Risks, and Open Questions
Commercialization hinges on closing power, cost, and operations gaps while proving multi-vendor interoperability at scale.
Energy Efficiency and TCO for GPU DUs
GPUs must compete with ASIC and FPGA accelerators on watts per cell and site cooling, especially for dense macro deployments. Power optimizations, workload partitioning across CPU/GPU/DPU, and AI-driven energy savings will be scrutinized in operator trials.
Determinism, Latency, and Timing Budget
Maintaining sub-millisecond deadlines with consistent latency jitter across varying traffic mixes is critical; production deployments will require rigorous benchmarking for both downlink and uplink, including uplink MU-MIMO and HARQ-heavy scenarios.
Fronthaul, eCPRI, and DU Pooling Limits
Aggregating multiple O-RUs per DU raises requirements for eCPRI capacity, precision timing (PTP/SyncE), and transport QoS. Operators must validate how far they can stretch DU centralization before latency budgets break.
O-RU Interoperability, RIC Integration, and Automation
Multi-vendor O-RU integration under O-RAN Split 7.2x, alignment with near-real-time RIC/xApps, and lifecycle automation across CI/CD pipelines will determine operational viability. Tooling for observability, performance regression, and closed-loop optimization must mature.
GPU Supply, Cost, and Platform Availability
GPU availability, cost volatility, and platform standardization will influence rollout pacing, particularly if AI workloads share the same accelerators as L1 processing at the edge.
Next Steps and 2026 Roadmap
Operators and suppliers should translate the milestone into actionable trials, architecture choices, and procurement plans for 2026.
Operator Actions: POCs, Power, and Benchmarks
Stand up POCs for GPU-based DUs in urban macro with 64T64R radios, validate 16-layer MU-MIMO outdoors, and baseline power, capacity, and latency versus incumbent L1 accelerators. Prioritize O-RAN 7.2x RUs, tight timing, and transport designs, and integrate with RIC for AI-driven beam and interference control.
Vendor Actions: Deterministic L1 and CI/CD
Harden software stacks for deterministic L1 on GPUs, certify multi-vendor O-RUs, and build runbooks that combine AI inference with real-time PHY processing. Invest in observability, energy optimization, and CI/CD pipelines that support rapid feature iteration without service risk.
Milestones: Trials, Benchmarks, and Interoperability
SoftBank targets commercial introduction from 2026 and is showcasing the system at NVIDIA GTC in Washington, D.C. this week. Track additional operator field trials, published power and performance benchmarks, uplink MU-MIMO maturity, and broader O-RU interoperability results as indicators of market readiness.