Why Lumen 400G metro connectivity matters for AI now
AI buildouts and multi-cloud scale are stressing data center interconnect, making high-capacity, on-demand metro connectivity a priority for enterprises.
The AI bandwidth and latency crunch in metro interconnect
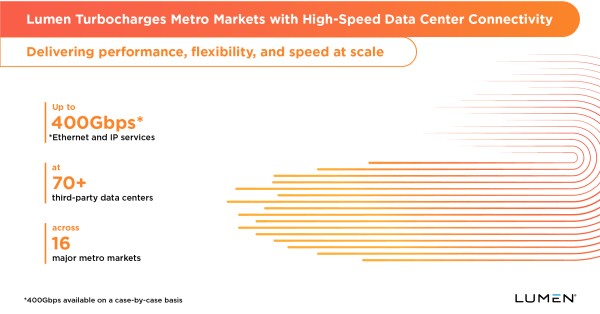
Training pipelines, retrieval-augmented generation, and model distribution are shifting traffic patterns from north-south to high-volume east-west across metro clusters of data centers and cloud on-ramps. As GPU clusters proliferate and inference moves closer to users, enterprises need predictable, low-latency links between colocation sites and hyperscale entrances, plus the ability to spin up capacity quickly and pay only for what is used. This is the backdrop for Lumen Technologies’ push to deliver up to 400Gbps Ethernet and IP Services in more than 70 third-party, cloud on-ramp-ready facilities across 16 U.S. metro markets.

Why owning metro fiber and automation is a win for AI timelines
Capacity alone is not enough; control over the underlying fiber, automation to turn up circuits in minutes, and consistent performance across markets determine whether AI timelines slip or ship. Lumens moves leverages its owned network footprint, giving enterprises a single operational model from on-ramps to long-haul and edge, which is increasingly valuable as AI programs scale across multiple clouds and geographies.
Lumen 400G-ready metro data center interconnect
Lumen is expanding metro data center connectivity with on-demand 400G-ready services designed for AI-scale workloads and multi-cloud interconnect.
Markets and cloud on-ramp locations
The company is lighting up more than 70 third-party data centers with high-speed access across Northern Virginia, Atlanta, Chicago, Columbus, Dallas, Denver, Kansas City, Las Vegas, Los Angeles, Minneapolis, New York City, Phoenix, Portland, San Jose, Seattle, and San Antonio, with San Antonio slated for availability in the fourth quarter of 2025. The focus is cloud on-ramp proximity and dense interconnect in AI-heavy metros, aligning with where enterprises are clustering GPUs and storage for model training and serving.
On-demand Ethernet/IP services and pricing
Enterprises can tap Ethernet On-Demand and Internet On-Demand to activate capacity in near real time, and use E-Line for point-to-point transport, E-LAN for multipoint connectivity, and E-Access to extend reach into broader Ethernet footprints. The draw is operational agility: bandwidth provisioning in minutes, scaling up to 400Gbps per service, and consumption-based pricing that aligns spend with variable AI and data movement spikes. Because Lumen owns and operates the network, customers consolidate SLAs and gain more predictable performance versus piecing together multiple partners.
How 400G reshapes AI and multi-cloud architectures
The expansion changes how teams design data pipelines, model placement, and interconnect strategy across metro and edge domains.
Data gravity and high-throughput AI pipelines
AI pipelines move petabytes between data lakes, feature stores, GPU clusters, and cloud regions, so 100G and 400G circuits are becoming the baseline for data ingest, checkpoint syncs, and distributed training. High-capacity Ethernet and IP services let architects right-size lanes between colocation and cloud on-ramps such as AWS Direct Connect, Microsoft Azure ExpressRoute, Google Cloud Interconnect, Oracle FastConnect, and IBM Cloud connections, while keeping jitter and packet loss in check for GPU utilization. In practice, this can reduce job completion times and lower cloud egress costs by placing staging and caching near on-ramps.
Sub-5ms latency, edge placement, and inference
Lumens network is engineered to deliver sub-5 millisecond edge latency to cover the vast majority of U.S. enterprise demand, which matters for real-time inference, personalization, and streaming analytics. When paired with metro 400G links, organizations can distribute inference across multiple colos and clouds in a city, keep tail latencies within SLA, and fail over without shifting traffic across long-haul paths. This also supports hybrid patterns like serving models in one cloud while sourcing context from another, connected through deterministic metro transport.
Competitive landscape and Lumen differentiation
The 400G race spans carriers, neutral interconnection platforms, and SDN fabrics, and buyers should weigh control, reach, and automation across options.
Comparison with carriers and neutral fabrics
Neutral fabrics such as Equinix Fabric, Megaport, and PacketFabric offer fast virtual cross-connects among many providers; carriers, including AT&T, Verizon, and Zayo, deliver wave services and Ethernet with growing 400G footprints. Lumens’ angle is breadth plus ownership: connectivity to all major cloud providers, access into more than two thousand third-party data centers, over one hundred sixty thousand on-net enterprise locations, and a roadmap to expand intercity fiber miles materially by the end of 2028. For AI teams, consolidating metro, long-haul, internet, and security services with one network operator can simplify procurement and troubleshooting while preserving multi-cloud choice at the on-ramp layer.
What to evaluate beyond speed tiers
Aside from raw capacity, evaluate turn-up times, automation APIs, telemetry depth, and SLA enforcement. Ask how path diversity is engineered across conduits, what DDoS and volumetric attack protections are bundled, whether MACsec is available for L2 encryption, and how traffic engineering (for example, segment routing or EVPN underlays) optimizes latency and jitter at scale. These operational dimensions often matter more than a headline speed tier.
Buyer guidance for designing and procuring 400G metro links
Architects should align interconnect design with AI roadmaps, hardware refresh cycles, and cloud adjacency plans to capture the benefits of 400G.
400G design and procurement checklist
Map AI and data workloads to metro topology and identify which colos require 100G versus 400G lanes over the next 1224 months, then stage incremental upgrades to avoid forklift changes. Confirm optical handoff and optics compatibility at the port (for example, QSFP-DD FR4 or DR4 for 400GbE), and request latency, jitter, and packet loss SLAs per path. Validate support for MEF-aligned service definitions and ordering APIs to integrate with your automation, and test service activation times in a pilot. Ensure cloud on-ramp capacities and cross-connect processes meet burst needs, including change windows. Specify encryption (MACsec for L2, IPsec for L3), DDoS scrubbing options, and telemetry streaming for real-time visibility. For data center interconnect, clarify whether you will run your own 400G optics or consume managed waves; if you operate optics, consider 400ZR/ZR+ for metro and regional spans and verify vendor interoperability. Design for dual-homing across distinct facilities and diverse routes, and simulate failover of AI inference services to validate SLOs.
Cost optimization levers for AI networking
Use on-demand bandwidth to align spend with model training windows, and aggregate smaller circuits where practical to reduce per-bit costs. Place data preprocessing close to cloud on-ramps to minimize egress, and negotiate multi-metro commits to capture discounts while preserving flexibility to shift capacity as AI clusters scale. Track cross-connect, power, and space charges alongside network fees to avoid hidden TCO creep.
What to watch next in 400G and AI networking
Execution speed and product depth will determine whether this move translates into a sustained AI connectivity advantage.
Roadmap signals to monitor
Monitor the staged activation of San Antonio in late 2025, the pace of adding additional on-ramp-ready facilities in AI growth metros, and progress toward the expanded intercity fiber mileage target by 2028. Watch for deeper API exposure for lifecycle automation, expanded security and route optimization features, and potential 800G readiness as optics and switching mature. Pricing dynamics will remain fluid as rivals extend 400G footprints; expect enterprises to benchmark Lumen against carrier wave services and neutral fabrics on time-to-turn-up, SLA adherence, and total cost per delivered Gbps.
Bottom line for telecom and IT leaders
AI scale is redefining metro interconnect as a strategic control point, and Lumens 400G expansion is a meaningful step that gives enterprises more headroom and agility near cloud on-ramps. The winners will pair capacity with automation, visibility, and resilient design, turning the network into an accelerator rather than a constraint for AI-first architectures.